如何用eclipse编写java代码,连接到本地的虚拟机集群,实现wordcount这个经典的例子?腾科教育小编告诉你,一起来看看吧。
1. 创建一个maven工程,然后导入相关的pom依赖
<repositories>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
</repositories>
<dependencies>
<!--mapreduce需要的jar-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.0-mr1-cdh5.14.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.0-cdh5.14.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.6.0-cdh5.14.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.6.0-cdh5.14.0</version>
</dependency>
2. 在eclipse中编写java代码:
public class WordCount {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// TODO Auto-generated method stub
//1.读取配置文件(知道hdfs在哪里)
Configuration conf =new Configuration();
//2.创建job
Job job=Job.getInstance(conf,"wordcount");
//3.设置job从哪里读数据,怎么处理数据,怎么输出
//input
Path inputPath = new Path(args[0]);
FileInputFormat.setInputPaths(job, inputPath);//读取文件规则,格式化
//map
job.setMapperClass(Map.class);//map用哪个类处理 null
//设置map的输出类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//reduce
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//output
Path outputPath = new Path(args[1]);
FileOutputFormat.setOutputPath(job, outputPath);
//任务提交
boolean isSuccess=job.waitForCompletion(true);
//成功就是0否则就是1
System.exit(isSuccess?0:1);
}
public static class Map extends Mapper<LongWritable,Text,Text,IntWritable>{
//定义 承接 输出参数的 变量
private final static IntWritable mapOutPutValue = new IntWritable(1);
private Text mapOutPutKey = new Text();
//写自己定义的Map的方法
@Override
public void map(LongWritable key ,Text value,Context context) throws IOException, InterruptedException {
String line = value.toString(); //将读取的 文本信息 转换成字符,也就是将行的内容转换成字符串
String[] words = line.split(" ");//将字符 截取成单词,split
//是否存在字符
if(words.length>0) {
//在进行统计 每个单词,对于数组有增强型的循环
for(String word : words) {
mapOutPutKey.set(word);
//通过次对象,将输出结果格式化成text
context.write(mapOutPutKey, mapOutPutValue);
}
}
}
}
public static class Reduce extends Reducer<Text,IntWritable,Text,IntWritable>{
//定义 承接 输出参数的 变量
private final static IntWritable SUM = new IntWritable(1);
//重写Reducer中的reduce方法
@Override
public void reduce(Text key,Iterable<IntWritable> values,Context context) throws IOException, InterruptedException {
//主要 对 每个 value 携带的 key 进行累加
int sum = 0;
for(IntWritable value : values) {
//sum = sum + value.get();
sum += value.get();
}
SUM.set(sum);
context.write(key, SUM);
}
}
}
3.将这个工程打成一个jar包上传到集群中
右键这个项目,选择export
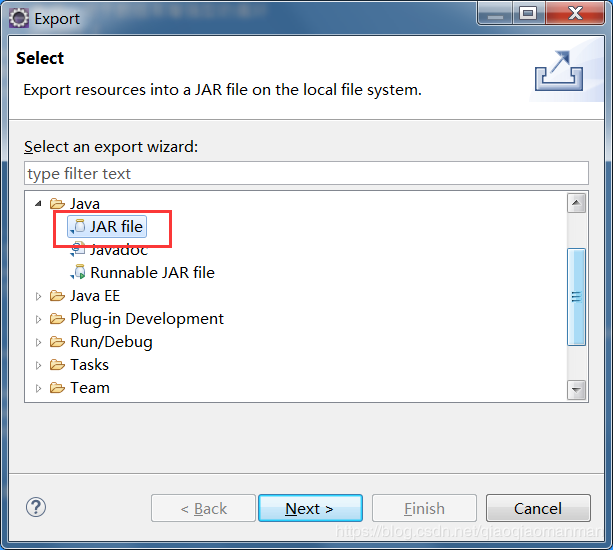
选中jar file然后下一步。
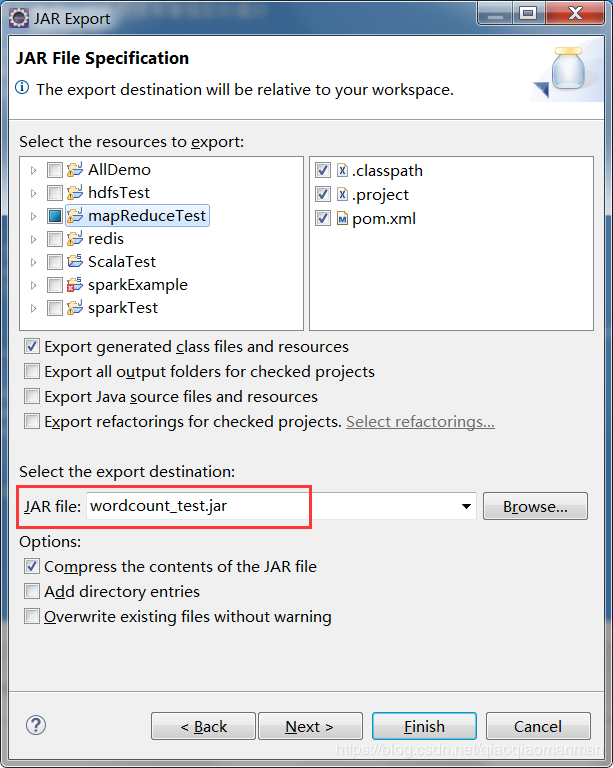
然后填写jar包名称。
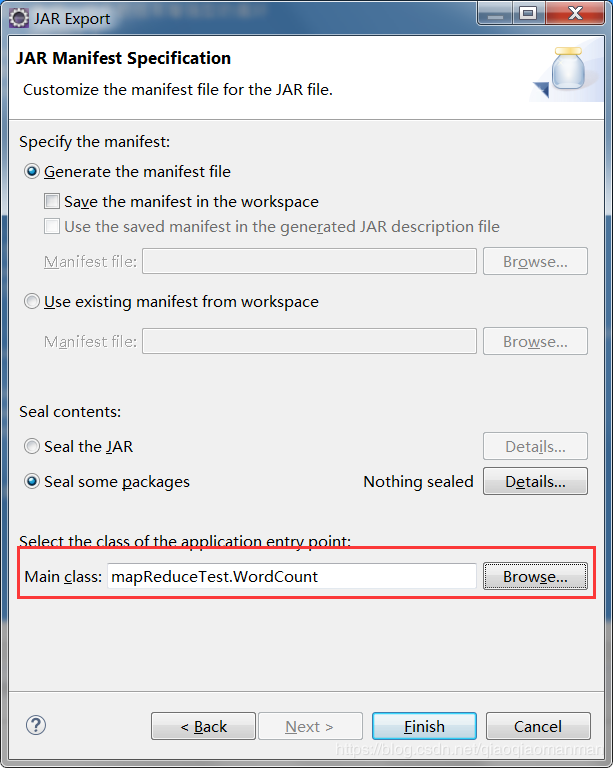
点击两次next,在上述界面中指定一个主类。
然后将这个jar包导入到集群中。
输入如下命令:
hadoop jar wordcount.jar +hdfs集群上的文件+一个不存在的目录
腾科教育小编提醒欢迎关注腾科教育淘宝:https://shop327449868.taobao.com/?spm=a1z10.1-c-s.0.0.38b449ecknqfoF / 微信公众号:腾科教育 / 抖音:腾科教育 / 新浪微博:腾科教育官微,获取更多资讯和实用干货。